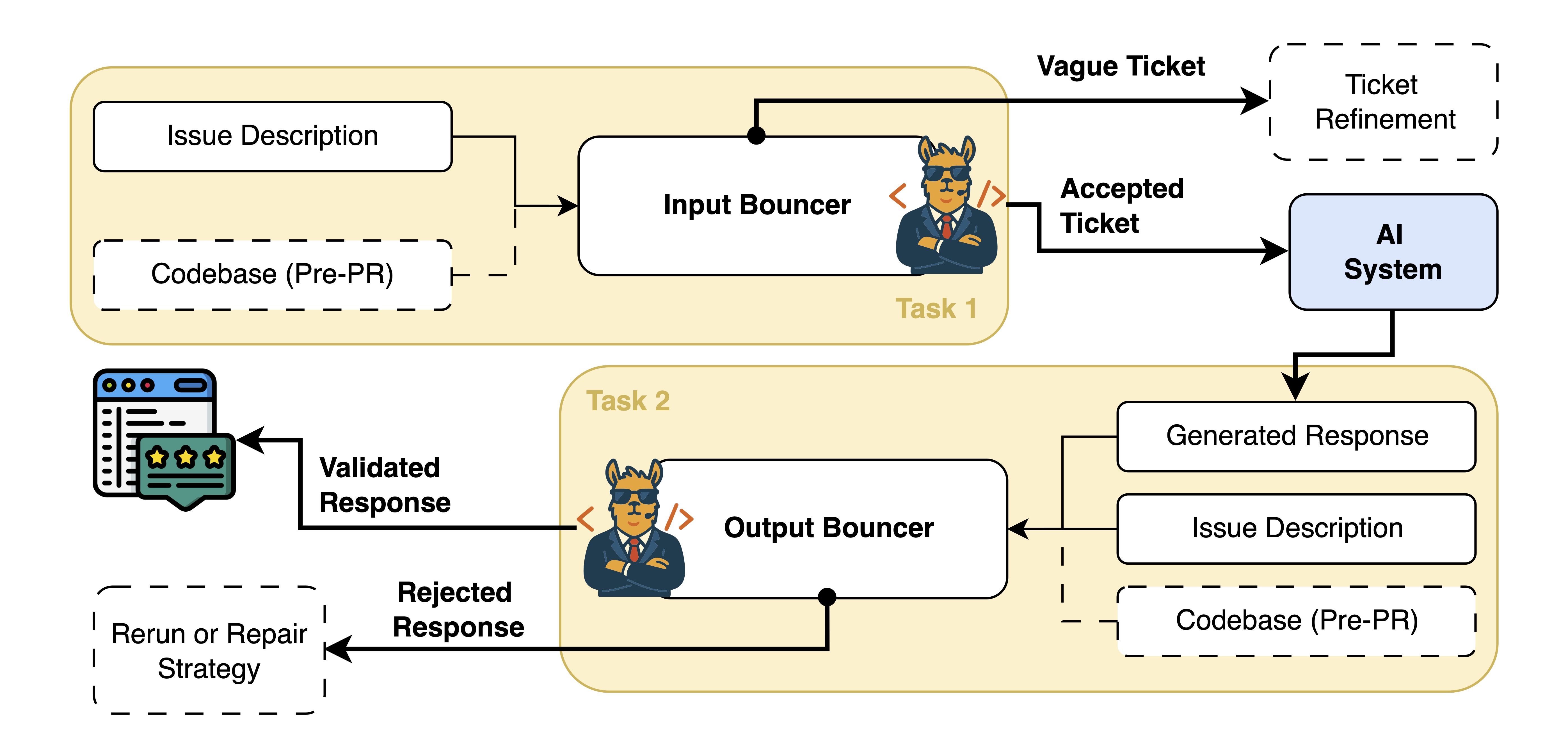
Large Language Models (LLMs) are being increasingly used in software engineering tasks, with an increased focus on bug report resolution over the past year. However, most proposed systems fail to properly handle uncertain or incorrect inputs and outputs. Existing LLM-based tools and coding agents respond to every issue and generate a patch for every case, even when the input is vague or their own output is incorrect. There are no mechanisms in place to abstain when confidence is low.
This leads to unreliable behaviour, such as hallucinated code changes or responses based on vague issue reports. We introduce BouncerBench, a benchmark that evaluates whether LLM-based software agents can refuse to act when inputs are ill-defined or refuse to respond when their own outputs are likely to be incorrect. Unlike prior benchmarks that implicitly incentivize models to generate responses even when uncertain, BouncerBench aims to improve precision by targeting two overlooked failure points:
(1) vague or underspecified issue descriptions in tickets
(2) logically or functionally incorrect code patches created by the system.
It measures whether proposed systems can distinguish actionable issues from vague tickets and valid patches from untrustworthy ones.
| Model ⇅ | Fm ⇅ | I-Score ⇅ | Rb (%) ⇅ | FNRa (%) ⇅ |
|---|
| Model ⇅ | Fm ⇅ | O-Score ⇅ | Rb (%) ⇅ | FNRa (%) ⇅ |
|---|
| Model ⇅ | Input Bouncer | Output Bouncer | ||||||
|---|---|---|---|---|---|---|---|---|
| Fm ⇅ | I-Score ⇅ | Rb (%) ⇅ | FNRa (%) ⇅ | Fm ⇅ | O-Score ⇅ | Rb (%) ⇅ | FNRa (%) ⇅ | |
Contribute your system's results to the BouncerBench leaderboard and help advance the state of AI-based software engineering.
@misc{mathews2025automatedsoftwareengineertrustworthy,
title={Is Your Automated Software Engineer Trustworthy?},
author={Noble Saji Mathews and Meiyappan Nagappan},
year={2025},
eprint={2506.17812},
archivePrefix={arXiv},
primaryClass={cs.SE},
url={https://arxiv.org/abs/2506.17812},
}